The doctoral thesis
Frank Schultz (2016): “Sound Field Synthesis for Line Source Array Applications in Large-Scale Sound Reinforcement”, University of Rostock, URN: urn:nbn:de:gbv:28-diss2016-0078-1
was finally released.
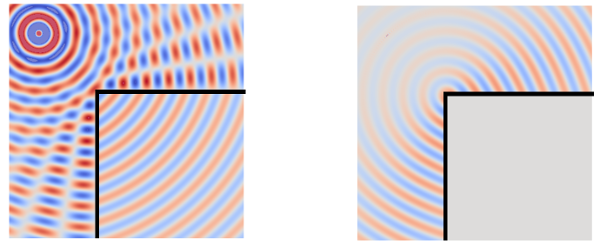
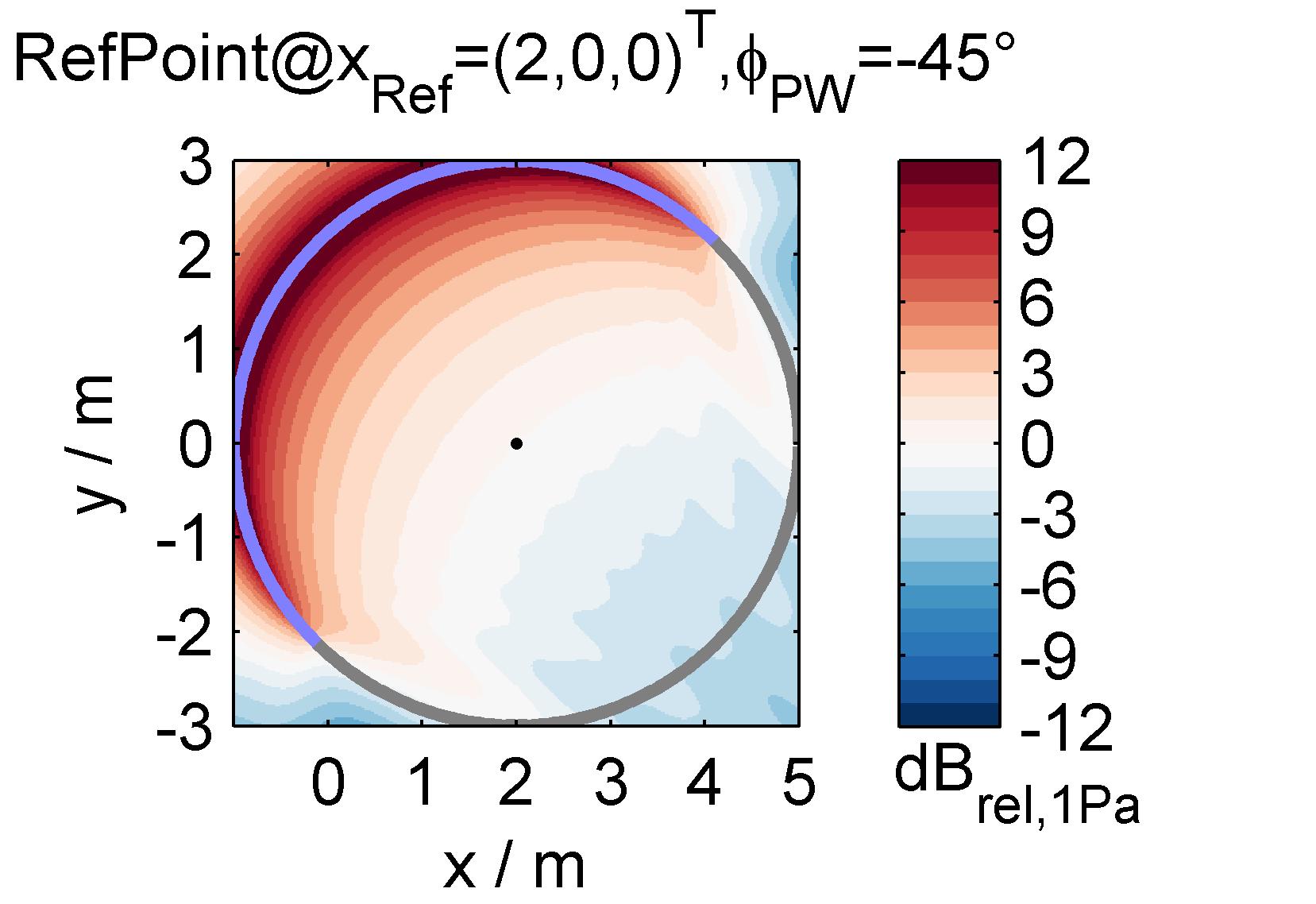
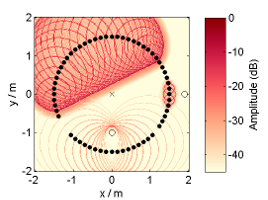
Abstract: This thesis deals with optimized large-scale sound reinforcement for large audiences in large venues using line source arrays. Homogeneous audience coverage requires flat frequency responses for all listeners and an appropriate sound pressure level distribution. This is treated as a sound field synthesis problem rather than a directivity synthesis problem. For that the synthesis of a virtual source via the line source array allows for interpreting the problem as audience adapted wavefront shaping. This is either achieved by geometrical array curving, by electronic control of the loudspeakers or by ideally combining both approaches. Obviously the obtained results depend on how accurately an array can emanate the desired wavefront. For practical array designs and setups this is affected by the deployed loudspeakers and their arrangement, its electronic control and potential spatial aliasing occurrence. The influence of these parameters is discussed with the aid of array signal processing revisiting the so called wavefront sculpture technology and proposing so called wave field synthesis as a suitable control method.